最近この本を読んだのですが、時系列分析の主要トピックを扱っている良書だなと思いました。

とにかく説明が丁寧で、数式や実例が駆使されて初めて触れる概念もすんなり理解できた気がしました。
本文では主にRでの実装が載っていますが、pythonでも出来そうだったので本文の流れに沿って実装してみたので紹介します。
ARIMA(第2部 6-14)
用いるデータセットはRに組み込まれているSeatbeltsです。こちらはweb上に公開されているのでダウンロードします。
curl -O https://raw.githubusercontent.com/jamovi/r-datasets/master/data/Seatbelts.csv mkdir input mv Seatbelts.csv ./input/
続いてpandasで読み込んでみます。
import pandas as pd import numpy as np import matplotlib.pyplot as plt import statsmodels.api as sm import pmdarima as pm path = "../input/Seatbelts.csv" df = pd.read_csv(path).drop("Unnamed: 0", axis=1) # 1969 ~ 1984年までの毎月のデータ # 手動で日付を付与 ymd = [] cnt = 0 for y in range(1969, 1985): for m in range(1, 13): ymd.append(pd.to_datetime(f"{y}-{m}-01")) cnt += 1 df["timestamp"] = ymd print(df.shape) display(df.head()) print(df.columns)
 主に使用する列は以下の3つです。
主に使用する列は以下の3つです。
- front
- 前席における死傷者数
- PetrolPrice
- ガソリンの値段
- law
- 前席においてシートベルトを着用することを義務付けた法律の施行の有無
死傷者数の推移をプロットしてみます。
plt.plot(df["timestamp"], df["front"]) plt.xlabel("ym") plt.ylabel("death and injury num") plt.show()

右下がりのトレンドのようです。
続いて、データの差分をとる必要があるか、KPSS検定で確認してみます。
# KPSS検定 # 帰無仮説: 単位根なし、対立仮説: 単位根あり stats, p_value, lags, crit = sm.tsa.kpss(df["front"]) print(f"stats: {stats}, p_value: {p_value}, lags: {lags}, crit: {crit}") >> stats: 1.550066754386029, p_value: 0.01, lags: 8, crit: {'10%': 0.347, '5%': 0.463, '2.5%': 0.574, '1%': 0.739}
統計量は有意水準を5 %としたときの棄却点を上回っており、帰無仮説は棄却されて単位根があるとみなせることが分かりました。
差分を取る前に元データで色々見てみます。
自己相関のグラフ
sm.graphics.tsa.plot_acf(df["front"], lags=24) sm.graphics.tsa.plot_pacf(df["front"], lags=24) plt.show()


短期の自己相関が多くみられますね。
データをトレンド成分、季節成分に分解
seasonal_decompose_res = sm.tsa.seasonal_decompose(df["front"], period=12) seasonal_decompose_res.plot() plt.show()

ここからは元データの差分系列を扱っていきます。
本によると、「個数や人数といったデータは対数変換してからモデル化するとうまくいく」とのことで、対数変換してから差分を取っていきます。
まずは差分系列を作成し、グラフで見てみます。
df["log_front"] = np.log(df["front"]) df["diff_log_front"] = df["log_front"] - df["log_front"].shift() plt.plot(df["timestamp"], df["diff_log_front"]) plt.xlabel("ym") plt.ylabel("death and injury num") plt.show()

長期にわたって平均値が一定に見えますね。
sm.graphics.tsa.plot_acf(df["diff_log_front"].dropna(), lags=24) plt.show()

差分系列は短期の自己相関が減りました。
しかし12か月単位の自己相関は残っているようです。
月ごとに分けたグラフを描いて確認してみます。
ついでに月ごとの平均値も見てみましょう。
month_name = ["Jan", "Feb", "Mar", "Apr", "May", "Jun", "jul", "Aug", "Sep", "Oct", "Nov", "Dec"] fig, ax = plt.subplots(3, 4, figsize=(16, 12)) # 月ごとにプロット for i in range(12): row = i // 4 col = i % 4 tmp = df.loc[df["month"] == i + 1] ax[row][col].plot(tmp["timestamp"], tmp["front"]) ax[row][col].set_title(month_name[i]) ax[row][col].set_ylim(400, 1400) print(f"{month_name[i]} average front: {tmp['front'].mean()}") plt.tight_layout() plt.show()
# 出力 Jan average front: 768.1875 Feb average front: 686.5 Mar average front: 735.25 Apr average front: 745.875 May average front: 833.3125 Jun average front: 815.0625 jul average front: 905.5 Aug average front: 938.5 Sep average front: 861.3125 Oct average front: 879.875 Nov average front: 893.25 Dec average front: 984.0

12月が最も死傷者数の多い月であることが分かります。
それでは先ほどの差分系列から、さらに季節成分を取ってみましょう。
# 季節成分(1年周期)を取ってみる df["diff_12_diff_log_front"] = df["diff_log_front"] - df["diff_log_front"].shift(12) sm.graphics.tsa.plot_acf(df["diff_12_diff_log_front"].dropna(), lags=24) sm.graphics.tsa.plot_pacf(df["diff_12_diff_log_front"].dropna(), lags=24) plt.show()


まだ季節成分が残っており、すべて取り除けてはいないようです。
さてここからはモデルを作成していきます。
ARIMAモデルが差分を取ってくれるので、対数変換したデータを使っていきます。
パラメータは教科書と同じものに設定します。
test_year = 1984 train = df.loc[df["timestamp"].dt.year != test_year].reset_index(drop=True) test = df.loc[df["timestamp"].dt.year == test_year].reset_index(drop=True) # order: (AR=p, 階差=d, MA=q) # seasonal_order: (AR=p, 階差=d, MA=q, 季節階差=m) model_sarimax = sm.tsa.arima.ARIMA( endog=train["log_front"], exog=train.loc[:, ["PetrolPrice", "law"]], order=(1, 1, 1), seasonal_order=(1, 0, 0, 12) ) res = model_sarimax.fit() print(res.summary())

lawの係数がマイナスになっており、法律の施行で死傷者数が減るということが分かりました。
また、Ljung-Boxという項目を見てみると、0.03でした。
これはLjung-Box検定で帰無仮説と対立仮説は以下の通りです。
- 帰無仮説:データは無作為
- lag 1 から lag m までのすべてで自己相関が 0
- 対立仮説:データは無作為ではない
- lag 1 から lag m までの自己相関のうち、少なくとも一つが 0 ではない
今回の結果では帰無仮説が棄却され、データにはまだ自己相関が残っているという結果となりました。
この辺はARIMAのパラメータを変えると解消されるかもしれません。
最後に、このモデルでtest期間の予測を行ってみます。
pred = res.forecast(len(test), exog=test.loc[:, ["PetrolPrice", "law"]]) plt.figure(figsize=(10, 8)) # plt.plot(train["timestamp"], train["log_front"], label="train") plt.plot(test["timestamp"], test["log_front"], label="test") plt.plot(test["timestamp"], pred.values, label="pred") plt.legend() plt.show()
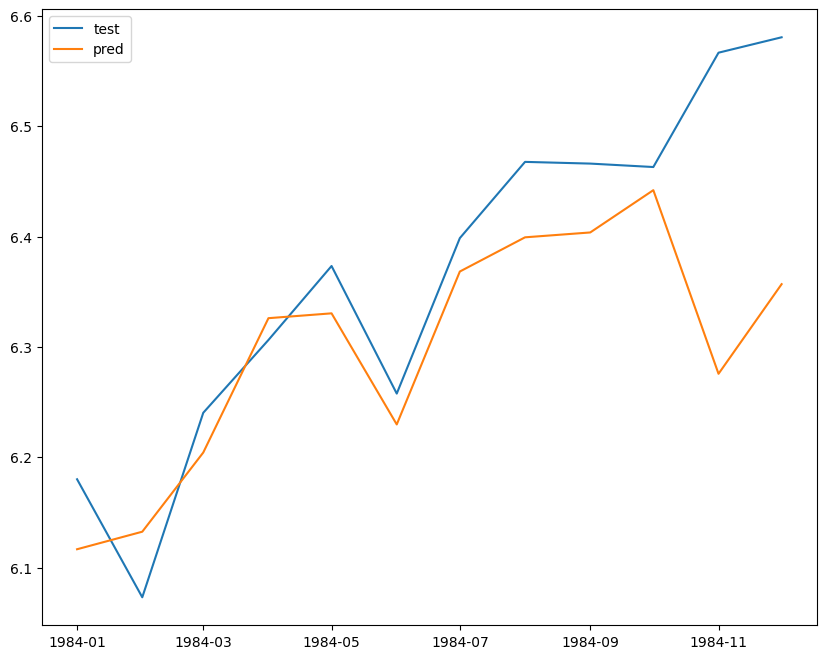
testデータ期間の前半はよさげですが、11, 12月の予測値は実測値と大きく異なってますね。今回のモデルでは年末にかけての動きをとらえることはできませんでした。
次は状態空間モデルをやってみます。